Miles de empleados analizando tus datos
La Inteligencia Artificial (IA) es una creación tecnológica humana capaz de hacer suposiciones y actuar por sí misma, facilitándole todas estas actividades.
Ejemplos de tareas en las que esto se lleva a cabo son el reconocimiento de voz, la visión por ordenador, la traducción entre lenguas (naturales) y otros mapeos de entradas.
Los distintos subcampos de la investigación en IA se centran en objetivos particulares y en el uso de herramientas concretas. Los objetivos tradicionales de la investigación en IA incluyen el razonamiento, la representación del conocimiento, la planificación, el aprendizaje, el procesamiento del lenguaje natural, la percepción y la capacidad de mover y manipular objetos.
La inteligencia general (la capacidad de resolver un problema arbitrario) es uno de los objetivos a largo plazo de este campo.
Para resolver estos problemas, los investigadores de la IA han adaptado e integrado una amplia gama de técnicas de resolución de problemas, como la búsqueda y la optimización matemática, la lógica formal, las redes neuronales artificiales y los métodos basados en la estadística, la probabilidad y la economía. La IA también se basa en la informática, la psicología, la lingüística, la filosofía y muchos otros campos.
Y eso significa que todos los datos que recopilan las empresas tecnológicas se envían a estas empresas de etiquetado de datos de IA que obtienen beneficios etiquetando tus imágenes, transcribiendo tus audios y fijando tu ubicación, tus compras en línea y tu historial de navegación.
IA como tecnología está en desarrollo, pero ya se aplica en muchas actividades humanas. Hay docenas de empresas que prestan servicios de etiquetado de datos para la industria de la IA.
Sí, tus datos se comparten con miles de empleados de empresas como Appen.
La mayoría de los algoritmos de maximización de beneficios, que sustentan los sitios de comercio electrónico, los asistentes de voz y los coches de conducción autónoma, se basan en el aprendizaje profundo, una técnica de IA que se basa en decenas de ejemplos etiquetados para ampliar sus capacidades.
La insaciable demanda ha creado la necesidad de una amplia base de mano de obra barata para etiquetar manualmente los vídeos, clasificar las fotos y transcribir el audio.
Se calcula que el valor de mercado de la contratación y coordinación de ese “trabajo fantasma”, como lo bautizaron la antropóloga Mary Gray y el científico social computacional Siddharth Suri, alcanzará los 13.700 millones de dólares en 2030.
Por ejemplo, a los fabricantes alemanes de automóviles, como Volkswagen y BMW, les entró el pánico de que los Teslas y Ubers del mundo amenazaran con hundir sus negocios. Así que hicieron lo que hacen las empresas tradicionales cuando se encuentran con una competencia de nuevo cuño: firmar cheques en blanco para mantener el ritmo.
Como todos los modelos de IA construidos sobre aprendizaje profundo, los coches autoconducidos necesitan millones, si no miles de millones, de ejemplos etiquetados para que se les enseñe a “ver.”
Estos ejemplos se presentan en forma de horas de vídeo: cada fotograma se anota cuidadosamente para identificar las marcas viales, los vehículos, los peatones, los árboles y los cubos de basura que el coche debe seguir o evitar. Pero, a diferencia de los modelos de inteligencia artificial que pueden clasificar ropa o recomendar artículos de prensa, los coches autoconducidos requieren la máxima precisión en las anotaciones. Un fotograma mal etiquetado puede suponer la diferencia entre la vida y la muerte.
Por ejemplo en Appen.
Tienen múltiples clientes tecnológicos, como Roomba, el robot de limpieza.
Roomba guarda imágenes de cada cliente y de su hogar.
Appen tiene la tarea de analizar y categorizar la información de las imágenes de millones de hogares con roombas.
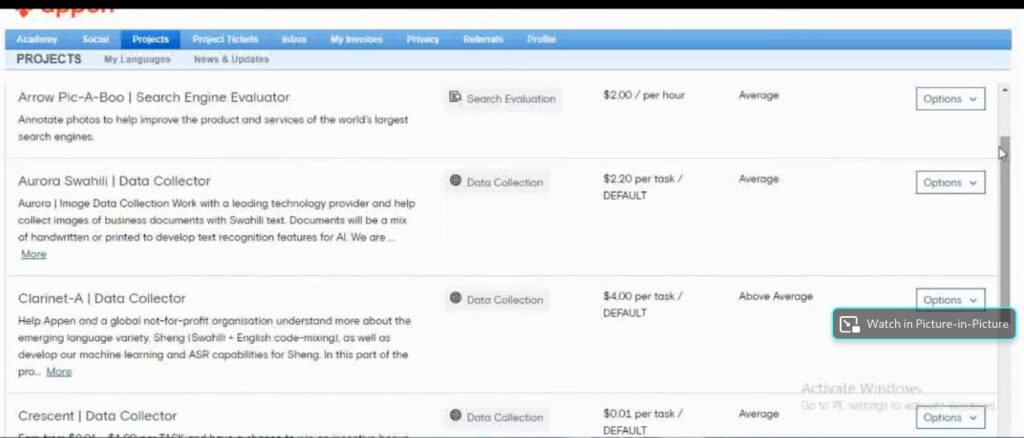
1. Un navegador muestra la cola de tareas en ejecución.
Cada uno muestra un título y un identificador de cliente anónimo, así como el número de unidades en que está dividido y cuánto pueden ganar (normalmente céntimos por unidad).
Las tareas son muy variadas, desde el etiquetado de imágenes a la moderación de contenidos, pasando por la categorización de productos (por ejemplo, determinar si un objeto de una foto pertenece a la categoría “joyas”, “ropa” o “bolsos”).
2. Para reclamar una tarea, hacen clic y el sistema presenta las instrucciones del cliente. A veces son claras, a veces no. A veces no hay ninguna.
Una de las trabajadoras dice que una de sus tareas ha resultado imposible:
Su pantalla se llena con una imagen de satélite de una zona muy boscosa.
No hay instrucciones, sólo una tecla que dice “árbol” y “no árboles”, y un cursor que le sugiere que perfile las partes correspondientes de la imagen.
Intente el método que intente, su respuesta ha sido rechazada todas las veces. Está convencida de que el cliente quiere que cada árbol -probablemente miles- se esboce individualmente.

3. Cuando completan la tarea, un recuento de sus ganancias en la esquina superior derecha sube en céntimos.
Estas industrias se llenaron primero de mano de obra barata procedente de Filipinas, Kenia y Venezuela.
Se trataba de encajes naturales, con historiales de subcontratación, poblaciones que hablan un inglés excelente y, sobre todo, salarios bajos.
En 2018, se estima que 200.000 venezolanos se habían registrado en Hive Micro y Spare5 otras empresas de etiquetado de datos de IA, lo que representa el 75% de sus respectivas plantillas.
Su tarea es sencilla pero requiere paciencia y tiempo, y se divierten un rato. Algunos de estos trabajadores están compartiendo imágenes preocupantes de su trabajo en las redes sociales. Una de las indirectas más famosas fue la foto de una mujer en el baño que un trabajador compartía en internet..
Las fotos fueron capturadas por iRobot y estan disponibles en el buscador de Google